Jasper Wang’s blog
In a quiet place, a person can hear his own thoughts.
Week 2 Sine Wave Exploring
Learning Progress
During last week, I am still trying to learn the whole machine learning process,it took me a long time to finish the Chapter 1 to 5. And I did repeat reading those chapters for many times to understand it better, but still I can’t squeeze all the steps in my mind, and certainly yet to write my own machine learning code. Luckily, the book makes every step clear, so I can understand most of the process now.
I think the “Hello World” is good example to get started, so I read all the codes, and follow the steps to train the modle.

I first update the Make on my Mac to version 4.3.
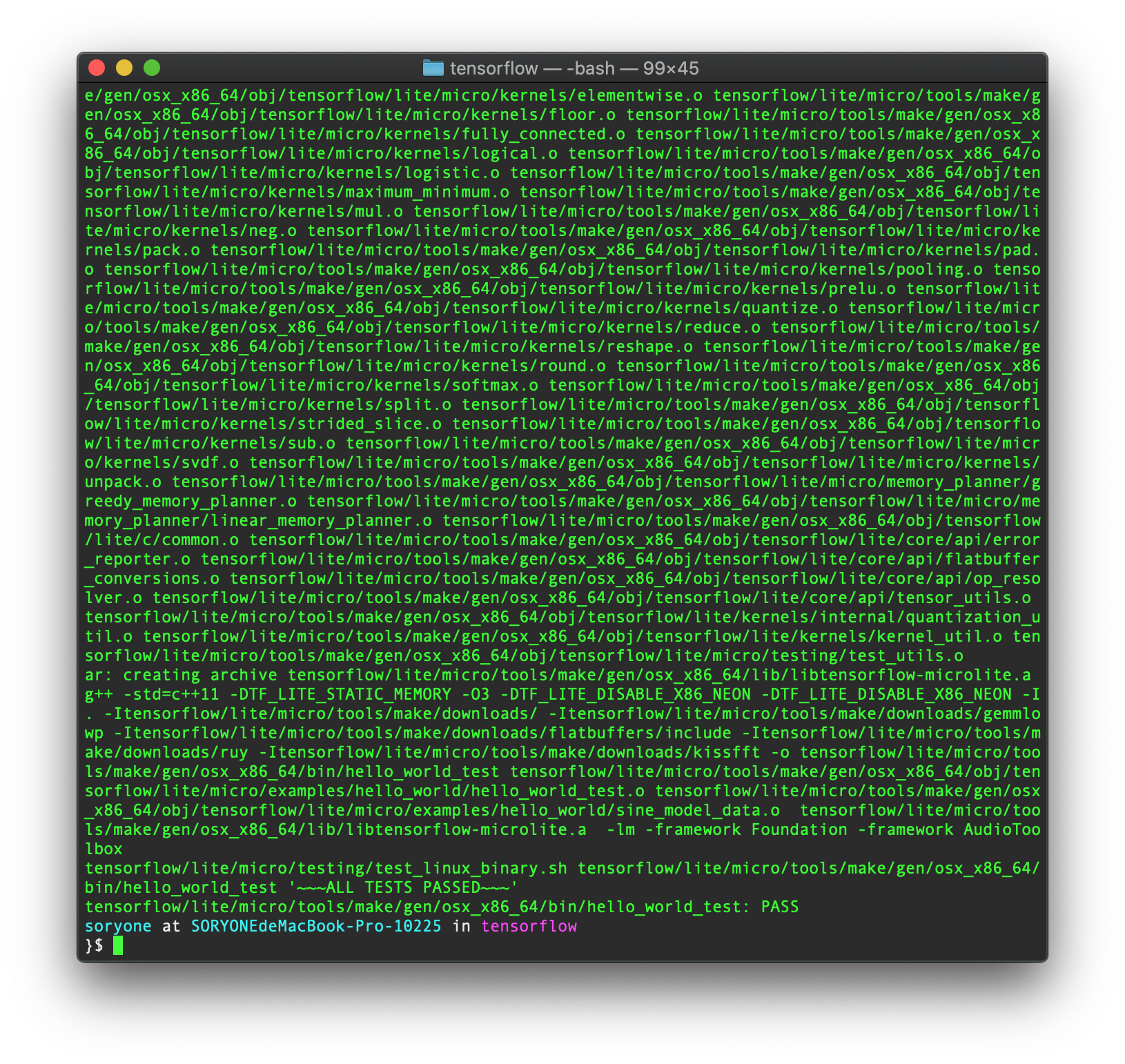
Then I run the test, which works fine.

Finally, I run the app, which infers the y value based on the x value I feed to the model.
Then I deployed it to the Ardunio, all the codes are provided in the example, and I can see there are more five files attched together. The arduino_output_handler is the one to control the LED, and the constants.cpp file includes the KInferencesPerCyle value which I can tweak to change the output speed, which ends up affecting the flicking interval of the LED.
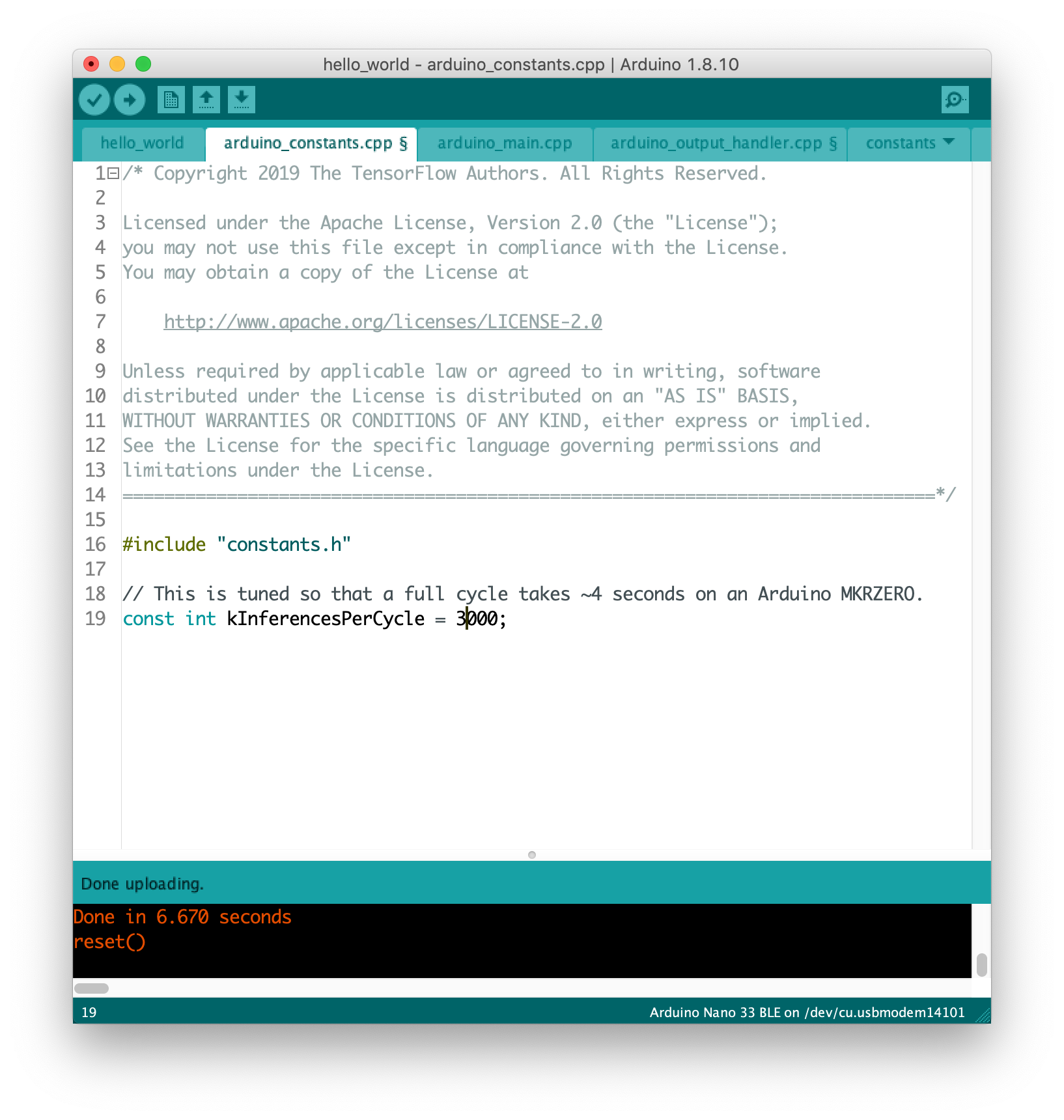
Here is the result.

Going back to the Gesture Recognition project
After the learning the Sine Wave Project, I went back to the first project I did on week one, I didn’t quite understand anything about learning and the code at that time, now I think I am getting a litte bit more clear. So I repeat the old steps, and realized a lot of things.
Why did I get the problem when training my data for the first time?
The first time I use Google Colab to train the data, I got nothing in the model.h file, so I turned to Yining twice, the issue she pointed out is that the model is not good enough to train my data, because the loss value didn’t keep going down around 0.

This chat visualizes the training progress.
You said:“the loss value didn’t go down and the model didn’t learn anything.”
However, I want to argue this point, I think from the pic, I can see the traning loss value actually went down a little bit, even it didn’t get closely enough to 0, but the model is still learned or improved something. But for sure, the result is not what we expected.
Another point is that the Validation loss kept going up until 100 epoches, which I think it indicates the model might have overfitted. It could also be a factor for the issued result I have.
Third, the model stopped improving after maybe 100 epoches, which I think we don’t have to set the epoch value to 600, maybe 300 will do the job.
To solve this issue, you suggested to add another layer in between the first and the output layer, that really solve the problem at that time. But I wonder do we have to add 30 tensors to it?
So I tried 3 different values in the second layer: 30,20 and 15.
I found that doing 20 tensors will get the same result, and the model also ended up smaller.

Last thing I tried is to narrow down the Epoches, I did it on 300, also I decrease the batch_size to 16.

This time the result is not good, I can see from the result, the inference is slight off the expected value.
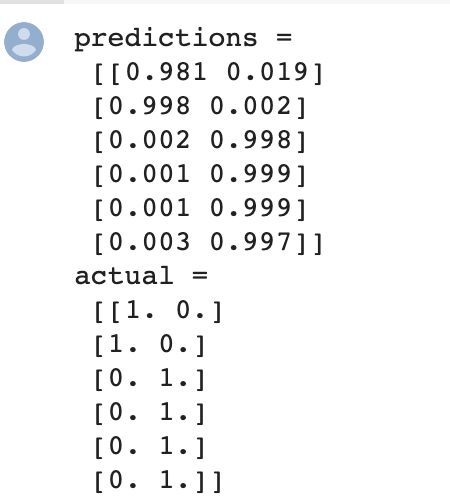
Anyway, I find it’s interesting to tweak these values during the training process. I still need to move on to catch up the next few chapters.